Frequently Asked Questions
General Questions
Tools for migrating data from an Archivists’ Toolkit instance to an ArchivesSpace instance will be released first to ArchivesSpace Charter members who will have exclusive access to the tools for the first 90 days after their release, followed by ArchivesSpace members who will have exclusive access for a second 90-day period. The migration tools will be made available to the general user community 180 days after their release. In the meantime, we have posted guidelines to help users prepare for migrating their Archivists’ Toolkit data at http://www.archivesspace.org/documents/preparing-data-for-migration-to-a....
- Login to post comments
A list of self-identifying AT users can be found here. If you are interested in identifying yourself and your repository to the larger AT community, please send us (info@archiviststoolkit.org) the name of your repository, the URL of the repository, and the name and contact information of the person best to contact with questions about your implementation of the AT.
- Login to post comments
The Archivists’ Toolkit™, or the AT, is the first open source archival data management system to provide broad, integrated support for the management of archives. It is intended for a wide range of archival repositories. The main goals of the AT are to support archival processing and production of access instruments, promote data standardization, promote efficiency, and lower training costs.
Currently, the application supports accessioning and describing archival materials; establishing names and subjects associated with archival materials, including the names of donors; managing locations for the materials; and exporting EAD finding aids, MARCXML records, and METS, MODS and Dublin Core records. Future functionality will be built to support repository user/resource use information, appraisal for archival materials, expressing and managing rights information, and interoperability with user authentication systems.
A single-page, double-sided informational sheet that provides an overview of the Archivists' Toolkit, including hardware and software requirements, is attached below.
The AT project is a collaboration of the University of California San Diego Libraries, the New York University Libraries and the Five Colleges, Inc. Libraries, and is generously funded by The Andrew W. Mellon Foundation.
If you are interested in identifying yourself and your repository to the larger AT community, please send us (info@archiviststoolkit.org) the name of your repository, the URL of the repository, and the name and contact information of the person best to contact with questions about your implementation of the AT.
| Attachment | Size |
|---|---|
| AT overview handout 2 0 Aug 2011 updated.doc | 227 KB |
- Login to post comments
- It is open source. You can download the application for free and have access to the source code.
-
It is designed for archivists by archivists. All members of the AT team have a significant amount of experience working in libraries and archives across the United States. The team also strives to include community feedback into the design and functionality of the program as much as possible.
It keeps your data in one place. Accessions information exists in the same database as descriptive information, and data re-use is prevalent throughout the application. Even donor information and location management is possible. - It makes authority control possible. The AT not only allows you to create authorized name and subject headings, thus reducing spelling and variant errors, but also enables you to see what materials in your repository are linked to those authorized headings.
- It produces EAD with the click of a button. It also exports MARC XML, and METS, MODS, and DC records for digital objects. In addition, there are 32 different reports available within the application, each of which is customizable.
- It is the ideal application for consortial environments. You can share your authority records with other repositories in your parent organization, thus providing data standardization at even higher levels.
- The interface and workflow are highly customizable. Set up your own custom data entry screens, re-label the fields to your choosing and more.
- Login to post comments
System Requirements for the AT Client
PC:
- Operating System: Windows 2000/XP/Vista
- Java 6 JRE or JDK
- CPU: Pentium 3, 500Mhz (recommend Pentium 4 2.4GHz+ or AMD 2400xp+)
- System Memory (RAM): 128MB (recommend 512MB)
- Hard Disk: 100MB free space
- Screen: 1024x768
Mac:
- Operating System: Mac OS X 10.3.9
- Java 6 JRE or JDK
- CPU: G3 500Mhz (recommend G4 1.2Ghz)
- System Memory (RAM): 256MB (recommend 512MB)
- Hard Disk: 100MB free space
- Screen: 1024x768
Supported Database Backends:
- MySQL 5.0 or 5.1 (with the InnoDB storage engine) NOTE: Only AT 2.0 update 11 and higher is compatible with MySQL 5.5
- MS SQL Server 2005 (or higher)
- Oracle 10g
- Login to post comments
If you log on as a superuser, you can see all of the usernames and reset any password you do not know. If you do not know the username or password of any superuser then you can find it by looking at the actual Users table in the database (you would most likely need to use a MySQL GUI to do this- Navicat or MySQL Administrator). If you know the password for a non superuser then you can make that user a superuser through the MySQL GUI program by changing the user's permission level to 5.
If you do not know the username or password for any user, there is no way to access the data without using the source code and programing a way around the password requirement. For security purposes, passwords are not stored in the database.
- Login to post comments
In MySQL, the case sensitivity of the underlying operating system plays a part in the case sensitivity of database and table names. Details about this can be found at here. Windows is case insensitive, however all table names are forced to lower case. When a database is transferred, the lowercase table names are transferred to Linux which is case sensitive and causes connection to the AT to fail. The recommended solution is to do a search and replace on the sql file and change all references to the mixed case we use for our table names. We know that this is tedious and we are thinking about adding a utility that can do this as part of our Maintenance Program.
- Login to post comments
The basic means for doing this consist of creating a backup of the data, and then using the data to create a new database in the desired location.
For MySQL:
- Create a MySQL dump using:
shell> mysqldump -u [username] -p[password] [database_name] > backup-file.sql
-
Load the SQL dump into a new (un-initialized) database:
shell> mysql -u [username] -p[password] [database_name] < backup-file.sql
Refer to the MySQL Backup and Recovery Documentation for more information.
- Login to post comments
In order for the AT team to fix bugs, it is essential that we be able to replicate them. This means that when you report bugs, it is critical that you include as much detail about the actions you completed prior to receiving a bug message. We realize that it may be difficult to remember those actions, and ask that once you receive a bug, to try and immediately replicate it and capture the actions upon replication.
Below is an example of a good bug report:
Resource index note item reference values unstable
Whenever index items are opened, their reference changes from the originally selected value to some other value. So if you set an index item to refer to an accruals note (ref7), close that index item and reopen it, the index item will no longer refer to an accruals note (ref7) but to some other note like the bibliography note (ref6).The steps I went through were:
1. Open resource
2. Create an index note (add title and note)
3. Add an index item: item 1, corporate name, referencing accruals note (ref7)
4. OK
5. Add an index item: item 2, corporate name, referencing bioghist note (ref46)
5. OK
6. Close index note (OK)
7. Close resource record (OK)
8. Reopen resource record
9. Open index note. In this view the references are still correct (ref7 and ref46)
10. Open item 1. The reference is now to bibliography note (ref6)
11. I then closed and reopened several times, trying both cancel and OK, they both had the same result.
12. Reopening the item the reference changed to ref5, then ref106, then ref101.If I cancel out of the whole resource record and do not save it, when I go back in the references are back to the values I originally set them to. But if the resource record is saved, the index values are incorrect.
In addition to including as much detail as possible in the bug report, it is also important to include your email address so that the team can contact you if we have further questions. We appreciate the extra effort it takes to create a good bug report; this effort reduces the amount of clarification needed by the AT team and helps us resolve bugs more quickly.
- Login to post comments
AT Usage Questions
This is a known problem with the display cutting off on the right side of Resource records (as of AT 2.0 update 13). You can drag the corner and to enlarge the screen size, but there are a couple of things to check. First, make sure that the screen resolution is at least 1024 x 768 (or higher). Second, shorten any custom RDE screen names to less than 20 characters.
Lastly, if you don’t use the new Scripting plugin for batch searching & replacing box numbers, go the AT program folder, open the plugins directory and delete the ‘ScriptAT.zip’ file. Then restart the AT and you should be able to see the complete Resource record without resizing.
- Login to post comments
If you receive the error message ‘Error connecting to database: database type is not supported’, when attempting to access a saved database connection, you can remedy the problem by editing the Windows registry. To manually remove the AT entry in the system registry, locate the information at:
HKEY_CURRENT_USER\Software\JavaSoft\Prefs\org\archiviststoolkit*
Once it has been deleted, restart the Toolkit and re-enter the connection settings.
If this does not fix the problem, then edit or delete the ‘atdbinfo.txt’ file. To locate the file 'atdbinfo', first, make sure the AT client is closed, then (on Windows machines) the user’s folder; for example, C:\Documents and settings\[username]/atdbinfo.txt. Once you have located the atdbinfo.txt file, you have two options: 1) open it and delete the connection setting that is faulty and any others you want to discard, or 2) simply delete the file (you can add re-save your connection settings again going forward).
With the file either deleted or edited and saved, re-launch the AT, and this should fix the problem.
*To modify the registry:
Click Start
Type REGEDIT
Click OK
The Registry Editor will now open
Locate the key (in this case, 'HKEY_CURRENT_USER') you wish to modify.
Click on the arrow to the left of the key to expand the directory and navigate to HKEY_CURRENT_USER\Software\JavaSoft\Prefs\org\archiviststoolkit
The values contained in the key will now appear in the right pane. Right-click the value you wish to modify or delete.
For MAC users, the problem can be remedied by deleting the file ‘com.apple.java.util.prefs.plist’, located in your Library/Preferences directory (for example, /Users/[your name]/Library/Preferences/com.apple.java.util.prefs.plist).
| Attachment | Size |
|---|---|
| FAQ editing atdbinfo.pdf | 389.62 KB |
- Login to post comments
The Archivists’ Toolkit now includes (AT 2.0, update 9 and later), support for an internal database based on HyperSQL 2.0 (HSQLDB). For installation instructions, click on the pdf below.
• If I am using the internal database, can I transfer to it data from another database such as MySQL, MS SQL Server, or Oracle?
No, we currently don’t support the migration of data between any of the database types supported by the AT, including the internal database.
• How much data can I store in the Internal Database?
The amount of data that can be stored is limited only by the available disk space on the user’s computer.
• How do I create a backup of the Internal Database?
First, shut down the AT if it is running. Then search for the “at_db” folder in your “Documents and Settings” folder if you use Windows, or in your home directory if you use Mac OS X or Linux. Once you locate the folder, create a zip archive of it. This is your backup file and it can be restored by simple deleting the "at_db" folder (if one exists), then unzipping it, in the same location. You can also move this backup file to another computer and unzip it in the appropriate folder as a way to share this data.
• How do I re-initialize the Internal Database and start fresh with an empty version?
In the event you need to re-initialize the Internal Database, simply delete the “at_db” folder and run the Maintenance Program to initialize it as before.
• If I upgrade my version of the AT and had an Internal Database setup, do I have to run the Maintenance Program again to initialize the Internal Database again?
No, updating the version of the AT, doesn't require the Internal Database to be initialized again.
• Can I provide access to the Internal Database over a network. For example, I want multiple people to share data like with MySQL, MS SQL Server, or Oracle?
Yes, since the Internal Database is based on HyperSQL, then it can be setup to allow network connections from multiple AT instances. However, we currently provide no technical support for doing this: you will have to consult the HyperSQL User Guide for information on how to accomplish this. Please note, that we advise only users with strong technical backgrounds to attempt this process.
| Attachment | Size |
|---|---|
| ATInternalDatabaseInstallationProcedures.pdf | 1.66 MB |
- Login to post comments
On a Macintosh:
- Right click on the AT application and select show contents
- In the contents folder open info.plist (this should launch the Property list editor)
- Open root -> java -> VMOptions
- Change -Xmx256M to either -Xmx512M or -Xmx1G depending on how much memory you want to allocate
On Windows XP (this should be the same for Vista)
- Open the Archivists Toolkit lax file in your favorite text editor
- Find the following line:
lax.nl.java.option.java.heap.size.max=
- Change the value which is expressed in bytes
256M = 268435456
512M = 536870912
1G = 1073741824
If this does not solve the memory problem, switch to a 64-bit Windows 7 machine using 64-bit JRE (the version that is bundled with the Archivists' Toolkit is 32-bit) which has at least 6GB of memory and change settings to something like:
4GB = 4294967296
- Login to post comments
This type of behavior is common if you are running a Macintosh system using Java 1.6. The next Java for Mac update will hopefully fix the problem. If you are not running a Macintosh please inform the AT team at info@archiviststoolkit.org.
- Login to post comments
Name records in the Archivists’ ToolkitTM are designed to conform with the International Council on Archives’ ISAAR(CPF): International Standard Archival Authority Record for Corporate Bodies, Persons, and Families, 2nd ed. and to support the proposed standard Encoded Archival Context (EAC). Name records also accommodate creation of names according to rules established in standards such as AACR2 and DACS.
The ISAAR (CPF) standard stands behind not only the AT but EAD as well. In compliance with the EAD standard, conferences are considered to be corporate names.
We recognize that choosing the international standard of ISAAR (CPF) over the national standard of AACR/MARC will force some modification of MARC records in which a conference name is encoded as a corporate name. Hopefully, that will be not either a great number of records or a very timely modification.
- Login to post comments
To fix this issue, you need to set at least one return screen value to something other than 0. The directions for this through Navicat are as follows:
- Find out the tableId of the table in the DatabaseTables table that is causing problems.
- In the DatabaseFields table use the Filter Wizard to filter for that tableId. It will look something like this tableId is equal to 43
- Set the return screen order of one of the fields to something other than 0.
- The database should now work.
Alternativly you can run the following sql command:
UPDATE DatabaseFields,DatabaseTables
SET DatabaseFields.returnScreenOrder = [new return screen order]
where DatabaseFields.fieldName='[field name]' and DatabaseFields.tableId = DatabaseTables.tableId and ->DatabaseTables.tableName='[table name]'
- Login to post comments
The most common reason for this is that one or both of the records you are trying to merge are not valid. This can also occur when you try to merge lookup list terms that are linked to invalid records. Invalid records are missing particular fields that are necessary for proper AT functioning. Currently the only invalid records that can be imported into the Toolkit are Name and Resource records. The import of invalid Names will be prevented in future versions of the AT.
To correct invalid records, open the record and add the information necessary to make it valid. To determine which fields are needed, simply try and save the record by clicking on the "OK" button. You will receive a message listing the fields necessary to produce a valid record.
- Login to post comments
Saving your work frequently helps guarantee that it will indeed be saved. Just like with any other software application, unexpected events can occur- computer crashes, power outages, etc., which can cause a loss of data. If you are using the Toolkit in any type of networked installation, it is especially necessary to save your work often as network connections can timeout or otherwise be interrupted. If you leave your computer for a long time, it is likely that the connection will time out and your data will be lost. Likewise, if your computer goes to sleep and the network connections are cut off, you will lose your data. It is recommended that you save your work often and especially anytime you get pulled away from your desk.
- Login to post comments
This is actually the correct behavior. After the Y2K issue the general consensus is that for years you have to explicitly enter all of the digits for the year you want. In this case if you simply enter "45" you are referring to the year 45 AD. The reason that you can enter more digits is that these are legitimate dates. Granted they are way in the future, but since we do not limit what the fields are used for there could be a reason to enter a year that far in the future. For most dates in the AT we do not allow entry of dates in the future. For the user defined dates this is not enforced again because we do not know what they are going to be used for.
- Login to post comments
Sadly this is a pretty complicated issue. The heart of it is that the ISO 8601 date standard is not implemented in any programming languages or relational database (to my knowledge). Even xml schema does not support all of it. Date ranges specifically are not supported in schema. This is why if you look at the declaration in the ead schema for normalized dates that the date datatype is not used. Since the normalized dates can't be stored or manipulated in anything other that a string field we would have write a bunch of custom programming and datatypes to handle the full range of the ISO standard. This would be a considerable amount of programming and testing to make sure we handled everything correctly. Actually I keep hoping that someone else will do the work in java and publish it as open source. Without that we have decided to only support the granularity of a 4 digit year for the normalized version. This way we can store them as integers and get strict typing without having to write extra code. We can always revisit this in the future but my guess is that it will be hard for it to float to the top of the priority list.
- Login to post comments
Import and Export Questions
If you are unable to import a valid EAD file on a Windows 7 machine, the problem could be due to local directory permissions. The application writes a file in the same directory as the source file. In Windows 7, the user needs to have explicit permission to write to the directory. If such permission is not explicit, the import will fail.
You can try placing the source EAD file and the ead.dtd on your desktop and then try to import into the AT. If this fails (or you have many EAD files to import), you need to add “Modify” right for the “User” group in order to have unrestricted admin access. This will let the AT read/write log files out of the application root: C:\Program Files\Archivists' Toolkit 2.0 (By default Windows 7 launches the AT in a restricted user context, so it can’t read/write *some* files in this location).
To modify this user setting, follow the instructions in the attached file
You can also right-click on AT program application icon in the AT Program folder and select 'Run as administrator' instead of 'Open'
| Attachment | Size |
|---|---|
| Win7ImportPermissionAT.pdf | 374.37 KB |
- Login to post comments
First, locate the report folder for your AT installation. The file path will probably look something like this:
C:\Program Files\Archivists' Toolkit 2.0\reports
Within this folder, you'll see sub folders for the different AT modules & records (Accessions, Assessments, DigitalObjects, General, Locations, Names, Resources & Subjects). Place the report file and any sub-report files into the report folder of the module it is associated with. For example, a Digital Object report should go into the DigitalObject folder.
It's important to note that the main report should only have .jrxml file while sub-reports will need to have a .jasper versions.
The .jasper version of a file is created when it is compiled, which can be done in iReports or through the AT client. If your sub-report(s) only has a .jrxml version, you'll need to compile it.
To do this:
- Open the AT client
- Select the menu option Reports -> Compile Jasper Report
- Select the sub-report(s)
- Click "Compile"
After any sub-reports which need compiling have been taken care of, select Reports -> Reload Reports in the AT client.
Your new report should appear in the reports drop down box for the relevant module.
If your new report does not show up in the appropriate drop down box, check that the report is in the correct report folder and that the main report does not have a compiled version (.jasper). The presence of a .jasper version of a main report will prevent it from showing up in the drop down menus of the application. If the later is the case, deleting the .jasper version of the report will fix the problem.
- Login to post comments
If there is a line break, or carriage return, after the value in the "Digital Object ID" field (formerly the METS ID field) the record can't be batch exported. The line break conflicts with the process for naming files generated from a batch export.
Removal of the line break will remedy the problem.
[This only applies to AT versions 2.0 and later since batch export of digital objects was not supported in previous versions.]
- Login to post comments
There are two types of legacy data that can be imported into the Toolkit: accessions data and description information. Accessions data can be imported by using a tab-delimited file or the XML schema included with the Toolkit program files. More information about both types of accessions data import can be found in the AT User Manual.
Descriptive data can be imported using valid EAD files or MARCXML. The AT development team may be able to assist with other types of data import, but there would be consulting costs associated with them. Please email info@archiviststoolkit.org for more information.
- Login to post comments
Is the EAD valid? Import of EAD's which do not validate against the EAD 2002 DTD or Schema is not supported by the AT. You can check this using an xml editor, which will list any validation errors present.
Do you have any extremely long chunks of text? While many of the AT's fields accommodate large amounts of data (roughly 10,000 words) they do have a limit on space. Check to see if you have any notes or other elements which have very long values. You can test this by (temporarily) removing large chunks of text and then seeing if the EAD can be imported. If this is the source of the problem, you can try splitting long notes into parts so the text is spread across multiple fields.
Have you edited your EAD document in Microsoft word? Word can sometimes interject characters which aren't supported by standard XML processors. An example being smart or curly quotes, rather than straight quotes. If possible, it is best to use an XML editor for working with EAD files to avoid such problems.
- Login to post comments
For EAD file conformant to the EAD DTD version 2002 (rather than the schema) the AT must be able to access the DTD.
The header of the EAD should include a doctype statement something like the following:
The last bit of text in quotations (above "ead.dtd") indicates where the AT should look for the DTD, this can be a url or file path. The example above indicates that the DTD is in the same folder as the EAD file. If the file is not in the location indicated you will be unable to import the file and get a message like this:
The document failed to import
C:\Documents and Settings\ahutt\Desktop\AT\AT Imports\ead\ead.dtd (The system cannot find the file specified)
If you are having problems with this, the easiest solution is to use the notation above ("ead.dtd") and place the DTD in the same folder as your EAD. The DTD can be accessed from the EAD web site. It is the first link in the list of files. Right click on the link and select "Save Link As…" to download.
- Login to post comments
First, locate the current stylesheets within the AT program directory. The file path will be something like: C:/Program Files /Archivists' Toolkit 2.0/Reports/Resources/eadToPDF
Both old and new stylesheets should have the exact same file name: at_eadToHTML.xsl and at_eadToPDF.xsl
Overwrite the old files with the new ones. It's not a bad idea to back up the default stylesheets, but these are included with the AT client so they can be retrieved by re-downloading the client, if necessary.
If the AT client is open, use the Reports drop-down option "Reload reports" to load the new stylesheets. This is located at the top title bar, in between the Setup and Help drop-down menus. This functionality is only available to high-level users. If you do not have the necessary access, you can close the AT and re-open it to reload the reports.
Test the new stylesheets by running finding aid reports.
- Login to post comments
Importing data in any fashion other than through the Import menu is highly discouraged. Using SQL commands to populate the database is especially fraught with problems and support cannot be guaranteed if that import method is chosen.
The AT API may be used to import legacy data, however the API is in fairly rough form at the moment and this type of import has not been tested. The AT technical staff may be able to assist with import for a negotiated fee.
- Login to post comments
Installation Questions
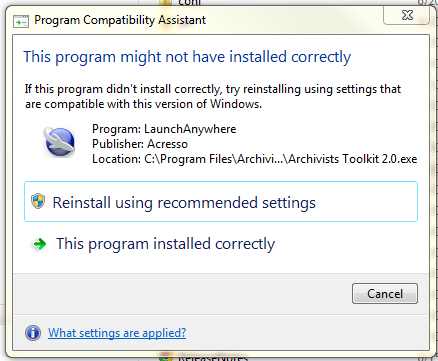
For Windows 7 users:
The "Program Compatibility Assistant" dialog box stating "This program might not have installed correctly" likely will appear when you close the AT application (see screenshot). To fix this problem, select "This program is installed correctly" marked with the green arrow. The dialog box should not longer appear when you close the application.
| Attachment | Size |
|---|---|
| ProgramCompatibilityAssistant.PNG | 39.04 KB |
{kind=link}
- Login to post comments
Java 1.5 is incompatible with AT 2.0 Update 14. To resolve this issue:
For Mac OSX 10.5 users running Java 1.5: Navigate to the directory where the Archivists' Toolkit program is installed, (usually "/Applications/Archivists Toolkit 2.0/"). Go to the 'plugins' directory and delete "scriptAT.zip".
For Mac OSX 10.6 and above are usually shipped with JRE 1.6 which is compatible with AT 2.0.
For Windows users running Java 1.5: Please upgrade to Java 1.6 or 1.7 or select the AT application download that includes Java VM (2nd selection). Newer Windows machines are usually shipped with Java 1.6 or Java 1.7 which are compatible with AT 2.0.
- Login to post comments
To uninstall a plugin, delete the *.zip file in the plugin directory, then restart the AT.
- Login to post comments
To install later versions of the AT (2.0, update 10 and later) on a Windows XP installation, edit the default (default=1024MB)Java heap space setting.
To change the Java heap space:
Open the Archivists’ Toolkit lax file in any text editor
Find the following line: lax.nl.java.option.java.heap.size.max=
Change the value (expressed in bytes)
512MB = 536870912
256MB = 268435456
- Login to post comments
With the release of AT 2.0 update 11, MySQL 5.5.x is now supported.
- Login to post comments
It is essential to backup your database before upgrade. Should the upgrade process fail, the database will be corrupted and a backup is necessary to continue the upgrade process. In short, should the upgrade process fail and there is no backup, all of your data may be lost.
- Login to post comments
The AT Maintenance Program bundled with the currently available AT 2.0 client application is designed to support upgrading an AT database from previous AT versions.
With the release of AT 2.0, the AT project team no longer works on new development, but does build maintenance releases when necessary. While the team will continue to support previous production versions of the AT, we encourage users to upgrade to the latest version, AT 2.0.14, and enjoy its improved functionality.
Please feel free to contact the AT team at info@archiviststoolkit.org if you have any questions or concerns.
- Login to post comments
For the AT to function, both the client and the database need to be at the same version. If you are running an older client on a database that has been upgraded, you will need to upgrade your client by downloading and installing the appropriate version from the AT download page.
Contact your database administrator if your database needs to be upgraded. Database upgrades are performed using the Maintenance Program located in the Toolkit program files. Please see our detailed upgrade instructions.
- Login to post comments
Currently (July, 2009) there is a problem with the bundled version of the program. If you receive this message, please do the following: 1. Uninstall the AT 2. Download the latest version of Java: http://www.java.com/en/ 3. Re-install the AT, selecting the version that does not include Java
- Login to post comments
The XAMPP distribution does not ship with InnoDB tables enabled in MySQL. This is required for the AT. To solve this problem, edit c:\xampp\mysql\bin\my.cnf, commenting out the "skip-innodb" line and uncommenting the other innodb configuration lines. Then restart the MySQL service, and the installation should go smoothly.
- Login to post comments
When installing on some flavors of Linux the following error message can come up. "awk: error while loading shared libraries: libdl.so.2". An AT user has posted the fix for this on his blog.
Here is an edited version.
The problem is, when you try to open and fix the .bin file in a text editor such as vi, it somehow mangles the code.
To fix the program:
- Backed up the installer to make sure that I didn’t have to re-download.
- Installed GHex, the Gnome Hex editor. If you’re using SUSE, you can install it with Yast. If you’re using Fedora, you can probably install it with Yum.
- Launch GHex, Click on File, then Open, and open the InstallArchivistsToolkit.bin install file.
- Left click on the right panel (ie. the one with characters that make sense.)
- Click on Edit, then replace.
- Type export LD in the right panel of the find section and #xport LD in the right panel of the replace section.
- Click on replace all.
- Cancel out of the replace dialog and save the file.
You should be able to run the file now. However, if you have to make this modification, you will also have to modify more of the Archivists’ Toolkit™ files in the exact same manner. I had to enter my Archivists_Toolkit directory and change both the Archivists_Toolkit and the AT_Initialize_Database files as well in order to get the program to run correctly. If in doubt about any part of the program, run that part from the command line, and watch for the results. If it fails because of this error, you will see awk: error while loading shared libraries: libdl.so.2 when it fails. If you see that, you know you need to edit the file.
- Login to post comments
If the stacktrace (details) of the message you are receiving contains a line that reads: "java.sql.SQLException: Table '[whatYouNamedYourDatabase].constants' doesn't exist" then you have not initialized the database. To initialize the database in AT version 1.1, use the Maintenance Program. To initialize the database in AT version 1.0, use the AT Initialize Database program. Both of these programs can be found in the same directory as the AT program files.
- Login to post comments
Application Bugs
Bug reports can
be transmitted using the bug report function in the application. Otherwise they should be sent to the AT project at info@archiviststoolkit.org
Other comments or questions should also be sent to info@archiviststoolkit.org
Copyright 2006-2009